In this section, we are going to scrape the data i.e. Tables data from Wikipedia using the various libraries and etc. Libraries like Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
The libraries used in the following project are:
Step1: Installing libraries and importing it
# Installation of libraries
!pip install beautifulsoup4 # It is used to install the beautifulsoup4
#Importing the installed BeautifulSoup and re
from bs4 import BeautifulSoup
import reStep 2: Using request re to fetch the website content via URL in text format.
requests is used to execute the url query and will fetch the given url website and transform into text format.
# Importing the Request, pages in text format
import requests as r
wikiURL="https://en.wikipedia.org/wiki/List_of_universities_in_Australia"
wiki_page_request = r.get(wikiURL)
wiki_page_text = wiki_page_request.textStep 3: Using the BeautifulSoup by transforming request fetched text to soup object or simply soup
It will fetch the given URL website content info and covert it into text and later it is converted into soup object which will later be used for content extraction.
# Using the BeautifulSoup
from bs4 import BeautifulSoup
import requests as r
wiki_page_request = r.get(wikiURL)
wiki_page_text = wiki_page_request.text
# New code below
soup = BeautifulSoup(wiki_page_text, 'html.parser')Step 4: This function will use soup object and extract data according to the given condition like: ‘class’:”wikitable” for extracting wikitable contained table.
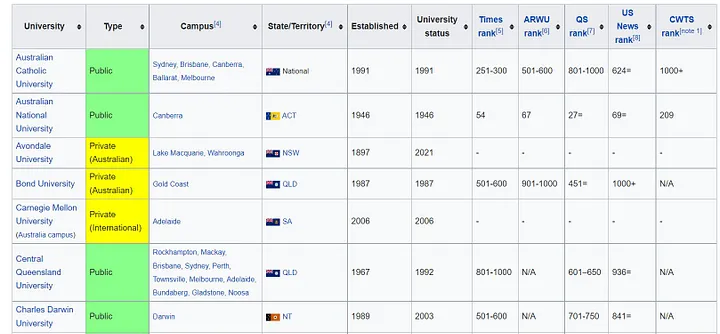
Below code will extract the content by wikitable class and first it will get header, first 6 header. for headersInit in headers: is done so that only header content can be extracted not [4] like extra text.
Then, rows is extracted using the “td” item and will get first 6 column data and in the case of Campus location if there is multiple values like:Lake Macquarie, Wahroonga then “…” will be done on that column values.
# Function that will give tables in operatable format
def returnTableData():
table = soup.find('table',{'class':"wikitable"})
headers = [header.text.strip() for header in table.find_all('th')[0:6]]
index = 0
for headersInit in headers:
if re.search('\[',headersInit):
result = re.split('\[', headersInit, 1)
headers[index]=result[0]
index += 1
rows = []
# Find all `tr` tags
data_rows = table.find_all('tr')
for row in data_rows:
value = row.find_all('td')
beautified_value = [ele.text.strip() for ele in value[0:6]]
# Remove data arrays that are empty
if len(beautified_value) == 0:
continue
if("," in str(beautified_value[2])):
beautified_value[2]="..."
rows.append(beautified_value)
return headers,rowsStep 5: It will execute the returnTableData method and will save returned data into csv files.
It will execute the returnTableData method and will returns the headers and row and will save the returned data into csv file with filename ‘universityList.csv
# Creating an CSV Files
import csv
headers,rows =returnTableData()
with open('universityList.csv', 'w', newline="") as output:
writer = csv.writer(output)
writer.writerow(headers)
writer.writerows(rows)Step 6: Final Extracted Data into CSV Files Output
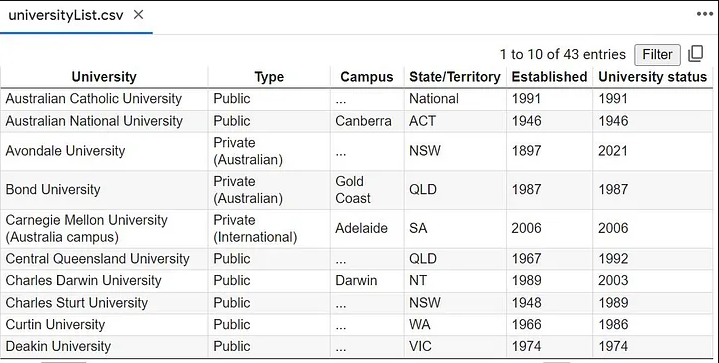
Below is the output csv files extracted from the given url wikipedia tables.
Please Follows Us in Linkeldn https://www.linkedin.com/in/rupesh-chaulagain-b3734a137/